8 Ficheros indicados no ordenados: árboles binarios
Para evitar tener que reconstruir el fichero de índices cada vez que se actualiza el archivo de datos existen varios métodos. Veremos ahora cómo implementar árboles binarios.
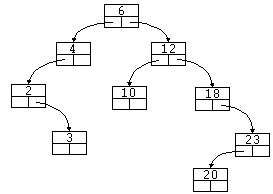
Para ello construiremos una estructura en árbol mediante una tabla almacenada en un archivo de disco.
La estructura para cada nodo del árbol es una extensión de la que usamos en el capítulo anterior, tan sólo añadiremos dos campos extra para apuntar a otros nodos:
struct stNodo {
char telefono[10];
long indice;
long menor, mayor;
};
Crearemos el fichero de índices estructurados en árbol a partir del archivo de datos, asignando a cada registro el campo "telefono" y el número de registro correspondiente y añadiendo los enlaces a otros nodos. Veamos un ejemplo:
000: [Fulanito] [Pérez] [Sanchez] [12345678] [Mayor] [15] [Lisboa] [19540425] [S] [0] 001: [Fonforito] [Fernandez] [López] [84565456] [Baja] [54] [Londres] [19750924] [C] [3] 002: [Tantolito] [Jimenez] [Fernandez] [45684565] [Alta] [153] [Berlin] [19840628] [S] [0] 003: [Menganito] [Sanchez] [López] [23254532] [Diagonal] [145] [Barcelona] [19650505] [C] [1] 004: [Tulanito] [Sanz] [Sanchez] [54556544] [Pez] [18] [Dublín] [19750111] [S] [0]
Veremos cómo se actualiza el fichero de índices a medida que insertamos registros en el archivo de datos:
Paso uno:
[12345678][000][---][---]
Paso dos:
[12345678][000][---][001] <-- [84565456][001][---][---]
Paso tres:
[12345678][000][---][001] [84565456][001][002][---] <-- [45684565][002][---][---]
Paso cuatro:
[12345678][000][---][001] [84565456][001][002][---] [45684565][002][003][---] <-- [23254532][003][---][---]
Paso cinco:
[12345678][000][---][001] [84565456][001][002][---] [45684565][002][003][004] <-- [23254532][003][---][---] [54556544][004][---][---]
Como puede observarse, cada vez que se inserta un registro de datos, tan sólo hay que insertar un registro de índice y modificar otro.
Eliminar registros
Supongamos que queremos eliminar un registro de datos. En el archivo de datos simplemente lo marcamos como borrado. En teoría, mientras el registro no se elimine físicamente, no será necesario eliminar el registro de índice asociado. Simplemente estará apuntando a un registro marcado como borrado. Posteriormente, cuando purguemos el archivo de datos será necesario reconstruir el fichero de índices.
Duplicación de claves
No hay inconveniente en almacenar registros con claves duplicadas, tan sólo habrá que tener en cuenta que tendremos que almacenar un nodo para cada uno de ellos. Tomaremos un criterio para el árbol, la rama 'menor', y pasará a ser la rama 'menor o igual'.
Ventajas y desventajas
Este método tiene la ventaja de que no es necesario ordenar el archivo de índices, pero puede producir resultados mediocres o francamente malos. Por ejemplo, si los registros se introducen ordenados, buscar por la clave del último registro insertado requerirá leer todos los nodos del árbol.
Para evitar eso se recurre a otros tipos de estructuras, como veremos en próximos capítulos.